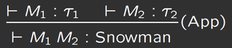
背景
- 「効率のよいデータ構造・アルゴリズム」を TeX 言語(や expl3 言語)で実装する機運が高まっている[1]。
- 複雑なデータ構造・アルゴリズムを実装する目的は優れた効率を得るためであり、それゆえ、「形だけ真似たが実装に問題があって本来の効率が得られていない」ようでは、そのデータ構造・アルゴリズムを実装する(少なくとも実用上の)意味はない。「ほぼ常に Θ(n2) 時間かかるクイックソート」の例が有名だろう。
- 従って「効率のよいデータ構造・アルゴリズムを TeX 言語で実装する話」をするためには、少なくとも「理論的な計算量を測る」手段があることが前提条件となる。(※以降では、漸近的な時間計算量に話を限る。)
- TeX 言語処理系の処理の様態は、通常の RAM 機械と比べると、自明に等価であるとはいえない。
- すなわち、TeX 言語における「計算のステップ数」の定義を決めたい。
※組版とは無関係な計算に限定する。(データ構造の話なので。)
2 つのモデル
組版処理を考えない場合は、TeX 処理系の動作は「トークンを実行すること」(展開可能トークンの場合は展開を実行と見なす)の繰り返しと見なすことができる。ここに着目した最も単純なモデルとして次のようなものを考える。
トークンの種類に関わらず、1 トークンの実行に 1 ステップかかる。
このモデルに従うと、例えば次のようなマクロ \S が定義されていた場合:
\def\S#1\E{}
以下の 2 つのプログラム(もちろん実質何もしない)の実行はどちらも 1 ステップとなる。
\S A\E
\S AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\E
これは不合理な気がする。TeX 処理系は \S を展開する際に、少なくとも全ての A を走査する必要がある。このような「トークンの読書き」にかかる時間を考慮したのが次のモデルである。
トークンの実行で m 個のトークンが読み込まれて n 個のトークンが書き出される場合、そのトークンの実行は m + n ステップかかる。
一般の TeX 処理系で漸近的な時間計算量を考える場合、①と②のどちらが妥当であろうか。
「トークンの読書き」の時間は無視できるかできないか
TeX プログラミングでデータ構造を表す場合に、「そのサイズに比例する長さのトークン列」が使われることはよくある。次に示す「\doリスト」はその一例である。
\do{2603}\do{26C4}\do{26C7}\do{1F363}\do{1F986}
従って、①と②のどちらを採用するかで、データ構造の実装の時間量に関する優劣の判断が異なってくる可能性は大きい。
もちろん、厳密に漸近的時間量をみるのであれば、「トークンの読書き」にかかる時間はゼロではないのだから、構造のサイズが増加していくと、最終的には「実行」よりも「読書き」の方が有意になり、従って②が妥当ということになるだろう。しかし現実的に考えると、TeX 処理系の実装上の空間量制限のもとでは、せいぜい数千のオーダのサイズのデータしか扱えそうにない。だから、「現実的な範囲」においては「読書き」の時間は無視できる、という可能性も捨てきれない。
チョット実験してみる
というわけで、調べてみた。
実験用文書“Len-n”(n=1,10,100,1000 を用意した)
\documentclass{article} \def\S#1\E{} \def\A{\S AAA……AAA\E}%←'A'をn個並べる \begin{document} \A\par %100万回繰り返す \A\par \A\par …… \end{document}
比較対照用文書“Base”
\documentclass{article} \def\S#1\E{} \def\A{} \begin{document} \par %100万回繰り返す \par \par …… \end{document}
- つまり、“Len-n”は“Base”と比べるとマクロ展開 200 万回分の処理が余計に必要になる。“Len-1”と“Len-1000”はトークン実行の回数は等しいが、“Len-1000”の方が「トークンの読書き」に時間がかかる。
- 従って、「“Base”対“Len-1”」の時間差と「“Len-1”対“Len-1000”」の時間差を比べれば、「現実的にトークンの読書きの時間が無視できるか」が判断できるはずである。
- TeX 処理系として TeX Live 2018 最新の latex コマンドを使った。
- 5 回のウォームアップの後、100 回のコンパイル時間を計測した。
結果
| 文書 | 所要時間平均(秒) | 標準偏差(秒) |
|---|---|---|
| Base | 2.285 | 0.016 |
| Len-1 | 2.490 | 0.027 |
| Len-10 | 2.640 | 0.019 |
| Len-100 | 4.111 | 0.025 |
| Len-1000 | 18.837 | 0.072 |
- Base と Len-1 の差: 0.205 秒
- Len-1 と Len-1000 の差: 16.347 秒
まとめ